Appendix A — Mathematics of linear regression
A.1 Least-squares estimators for simple linear regression
Below are the mathematical details for deriving the least-squares estimators for slope (\(\beta_1\)) and intercept (\(\beta_0\)) using calculus. We obtain the estimators \(\hat{\beta}_0\) and \(\hat{\beta}_1\) by finding the values of \(\beta_0\) and \(\beta_1\), respectively, that minimize the sum of squared residuals (Equation A.1).
Suppose we have a data set with \(n\) observations \((x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\). Then the sum of squared residuals is
\[ SSR = \sum\limits_{i=1}^{n}[y_i - \hat{y}_i]^2 = [y_i - (\beta_0 + \beta_1 x_i)]^2 = [y_i - \beta_0 - \beta_1 x_i]^2 \tag{A.1}\]
To find the value of \(\beta_0\) that minimizes Equation A.1, we begin by taking the partial derivative of Equation A.1 with respect to \(\beta_0\). Similarly, we take the partial derivative with respect to \(\beta_1\) to find the value of \(\beta_1\) that minimizes Equation A.1. The partial derivatives are
\[ \begin{aligned} &\frac{\partial \text{SSR}}{\partial \beta_0} = -2 \sum\limits_{i=1}^{n}(y_i - \beta_0 - \beta_1 x_i) \\[10pt] &\frac{\partial \text{SSR}}{\partial \beta_1} = -2 \sum\limits_{i=1}^{n}x_i(y_i - \beta_0 - \beta_1 x_i) \end{aligned} \tag{A.2}\]
Therefore, we want to find \(\hat{\beta}_0\) and \(\hat{\beta}_1\) that satisfy the following:
\[ \begin{aligned} &-2 \sum\limits_{i=1}^{n}(y_i - \hat{\beta}_0 - \hat{\beta}_1 x_i) = 0 \\[10pt] &-2 \sum\limits_{i=1}^{n}x_i(y_i - \hat{\beta}_0 - \hat{\beta}_1 x_i) = 0 \end{aligned} \tag{A.3}\]
Let’s focus on \(\hat{\beta}_0\) for now and find \(\hat{\beta}_0\) that satisfies the first equality in ?eq-par-deriv-estimators. The mathematical steps are below in Equation A.4
\[ \begin{aligned}&-2 \sum\limits_{i=1}^{n}(y_i - \hat{\beta}_0 - \hat{\beta}_1 x_i) = 0 \\[10pt] &\Rightarrow \sum\limits_{i=1}^{n}(y_i - \sum\limits_{i=1}^{n} \hat{\beta}_0 - \sum\limits_{i=1}^{n} \hat{\beta}_1 x_i) = 0 \\[10pt] &\Rightarrow \sum\limits_{i=1}^{n}y_i - n\hat{\beta}_0 - \hat{\beta}_1\sum\limits_{i=1}^{n}x_i = 0 \\[10pt] &\Rightarrow \sum\limits_{i=1}^{n}y_i - \hat{\beta}_1\sum\limits_{i=1}^{n}x_i = n\hat{\beta}_0 \\[10pt] &\Rightarrow \frac{1}{n}\Big(\sum\limits_{i=1}^{n}y_i - \hat{\beta}_1\sum\limits_{i=1}^{n}x_i\Big) = \hat{\beta}_0 \\[10pt] &\Rightarrow \bar{y} - \hat{\beta}_1 \bar{x} = \hat{\beta}_0 \\ \end{aligned} \tag{A.4}\]
The last line of Equation A.4 is derived from the fact that \(\bar{y} = \frac{1}{n}\sum_{i=1}^ny_i\) and \(\bar{x} = \frac{1}{n}\sum_{i=1}^n x_i\).
From Equation A.4, we know the \(\hat{\beta}_0\) that satisfies the first equality in Equation A.3 is
\[\hat{\beta}_0 = \bar{y} - \hat{\beta}_1\bar{x} \tag{A.5}\]
The formula for \(\hat{\beta}_0\) contains \(\hat{\beta}_1\), so now let’s find the value of \(\hat{\beta}_1\) that satisfies the second equality in Equation A.3. The mathematical steps are below in Equation A.6.
\[ \begin{aligned} &-2 \sum\limits_{i=1}^{n}x_i(y_i - \hat{\beta}_0 - \hat{\beta}_1 x_i) = 0 \\[10pt] &\Rightarrow \sum\limits_{i=1}^{n}x_iy_i - \hat{\beta}_0\sum\limits_{i=1}^{n}x_i - \hat{\beta}_1\sum\limits_{i=1}^{n}x_i^2 = 0 \\[10pt] \text{(Fill in }\hat{\beta}_0\text{)}&\Rightarrow \sum\limits_{i=1}^{n}x_iy_i - (\bar{y} - \hat{\beta}_1\bar{x})\sum\limits_{i=1}^{n}x_i - \hat{\beta}_1\sum\limits_{i=1}^{n}x_i^2 = 0 \\[10pt] &\Rightarrow \sum\limits_{i=1}^{n}x_iy_i = (\bar{y} - \hat{\beta}_1\bar{x})\sum\limits_{i=1}^{n}x_i + \hat{\beta}_1\sum\limits_{i=1}^{n}x_i^2 \\[10pt] &\Rightarrow \sum\limits_{i=1}^{n}x_iy_i = \bar{y}\sum\limits_{i=1}^{n}x_i - \hat{\beta}_1\bar{x}\sum\limits_{i=1}^{n}x_i + \hat{\beta}_1\sum\limits_{i=1}^{n}x_i^2\\[10pt] (\text{Given }\bar{x} = \sum_{i=1}^n x_i)&\Rightarrow \sum\limits_{i=1}^{n}x_iy_i = n\bar{y}\bar{x} - \hat{\beta}_1n\bar{x}^2 + \hat{\beta}_1\sum\limits_{i=1}^{n}x_i^2\\[10pt] &\Rightarrow \sum\limits_{i=1}^{n}x_iy_i - n\bar{y}\bar{x} = \hat{\beta}_1\sum\limits_{i=1}^{n}x_i^2 - \hat{\beta}_1n\bar{x}^2\\[10pt] &\Rightarrow \sum\limits_{i=1}^{n}x_iy_i - n\bar{y}\bar{x} = \hat{\beta}_1\Big(\sum\limits_{i=1}^{n}x_i^2 -n\bar{x}^2\Big)\\[10pt] &\Rightarrow \frac{\sum\limits_{i=1}^{n}x_iy_i - n\bar{y}\bar{x}}{\sum\limits_{i=1}^{n}x_i^2 -n\bar{x}^2} = \hat{\beta}_1 \end{aligned} \tag{A.6}\]
We will use the following rules to write Equation A.6 in a form that is more recognizable:
\[ \sum_{i=1}^n x_iy_i - n\bar{y}\bar{x} = \sum_{i=1}^n(x_i - \bar{x})(y_i - \bar{y}) = (n-1)\text{Cov}(x,y) \tag{A.7}\]
\[ \sum_{i=1}^n x_i^2 - n\bar{x}^2 = \sum_{i=1}^n(x_i - \bar{x})^2 = (n-1)s_x^2 \tag{A.8}\]
where \(\text{Cov}(x,y)\) is the covariance of \(x\) and \(y\), and \(s_x^2\) is the sample variance of \(x\) (\(s_x\) is the sample standard deviation).
Applying Equation A.7 and Equation A.8 to Equation A.6, we have
\[ \begin{aligned} \hat{\beta}_1 &= \frac{\sum\limits_{i=1}^{n}x_iy_i - n\bar{y}\bar{x}}{\sum\limits_{i=1}^{n}x_i^2 -n\bar{x}^2} \\[10pt] &= \frac{\sum\limits_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y})}{\sum\limits_{i=1}^{n}(x_i-\bar{x})^2}\\[10pt] &= \frac{(n-1)\text{Cov}(x,y)}{(n-1)s_x^2}\\[10pt] &= \frac{\text{Cov}(x,y)}{s_x^2} \end{aligned} \tag{A.9}\]
The correlation between \(x\) and \(y\) is \[r = \frac{\text{Cov}(x,y)}{s_x s_y}\]
Therefore, \[\text{Cov}(x,y) = r s_xs_y\]
where \(s_x\) and \(s_y\) are the sample standard deviations of \(x\) and \(y\), respectively.
Plugging in the formula for \(Cov(x,y)\) into Equation A.9, we have
\[ \hat{\beta}_1 = \frac{\text{Cov}(x,y)}{s_x^2} = r\frac{s_ys_x}{s_x^2} = r\frac{s_y}{s_x} \]
We have found values of \(\hat{\beta}_0\) and \(\hat{\beta}_1\) that satisfy Equation A.3. Now we need to confirm that we have found the minimum value (rather than a maximum value or saddle point). To do, we use the second partial derivative. If it is positive, then we know we have found a minimum.
The second partial derivatives are
\[ \begin{aligned} &\frac{\partial^2 \text{SSR}}{\partial \beta_0^2} = \frac{\partial}{\partial \beta_0}\Big(-2 \sum\limits_{i=1}^{n}(y_i - \beta_0 - \beta_1 x_i)\Big) = 2n > 0 \\[10pt] &\frac{\partial^2 \text{SSR}}{\partial \beta_1^2} = \frac{\partial}{\partial \beta_1}\Big(-2 \sum\limits_{i=1}^{n}x_i(y_i - \beta_0 - \beta_1 x_i)\Big) = 2\sum_{i=1}^nx_i^2 > 0 \end{aligned} \tag{A.10}\]
Both partial derivatives are greater than 0, so we have shown that the estimators \(\hat{\beta}_0\) and \(\hat{\beta}_1\), in fact, minimize SSR.
The least-squares estimators for the intercept and slope are
\[ \hat{\beta}_0 = \bar{y} - \hat{\beta}_1\bar{x} \hspace{20mm} \hat{\beta}_1 = r\frac{s_y}{s_x} \]
A.2 Matrix representation of linear regression
The matrix representation for linear regression introduced in this section will be used for the remainder of this appendix and in Appendix B. We will provide some linear algebra and matrix algebra details throughout, but we assume understanding of basic linear algebra concepts. Please see Chapter 1 An Introduction to Statistical Learning and online resources for an in-depth introduction to linear algebra.
Suppose we have a data set with \(n\) observations. The \(i^{th}\) observation is represented as \((x_{i1}, \ldots, x_{ip}, y_i)\), such that \(x_{i1}, \ldots, x_{ip}\) are the predictor variables and \(y_i\) is the response variable. We assume the data can be modeled using the least-squares regression model of the form in Equation A.11 (see Chapter 8 for more detail).
\[y_i = \beta_0 + \beta_1 x_{i1} + \dots + \beta_p x_{ip} + \epsilon \hspace{8mm} \epsilon \sim N(0, \sigma^2_{\epsilon}) \tag{A.11}\]
The regression model in Equation A.11 can be represented using vectors and matrices.
\[\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon} \hspace{8mm} \boldsymbol{\epsilon} \sim N(\mathbf{0}, \sigma^2_{\epsilon}\mathbf{I}) \tag{A.12}\]
Let’s break down the components of Equation A.12.
\[ \underbrace{ \begin{bmatrix} y_1 \\ \vdots \\ y_n \end{bmatrix} }_ {\mathbf{y}} \hspace{3mm} = \hspace{3mm} \underbrace{ \begin{bmatrix} 1 &x_{11} & \dots & x_{1p}\\ \vdots & \vdots &\ddots & \vdots \\ 1 & x_{n1} & \dots &x_{np} \end{bmatrix} }_{\mathbf{X}} \hspace{2mm} \underbrace{ \begin{bmatrix} \beta_0 \\ \beta_1 \\ \vdots \\ \beta_p \end{bmatrix} }_{\boldsymbol{\beta}} \hspace{3mm} + \hspace{3mm} \underbrace{ \begin{bmatrix} \epsilon_1 \\ \vdots\\ \epsilon_n \end{bmatrix} }_{\boldsymbol{\epsilon}} \tag{A.13}\]
From Equation A.12 and Equation A.13, we have the following components of the linear regression model in matrix form:
- \(\mathbf{y}\) is an \(n \times 1\) vector of the observed responses.
- \(\mathbf{X}\) is an \(n \times (p + 1)\) matrix called the design matrix. The first column is always \(\mathbf{1}\), a column vector of 1’s, that corresponds to the intercept. The remaining columns contain the observed values of the predictor variables.
- \(\boldsymbol{\beta}\) is a \((p+1) \times 1\) vector of the model coefficients.
- \(\boldsymbol{\epsilon}\) is an \(n \times 1\) vector of the error terms.
As before the error terms are normally distributed, centered at \(\mathbf{0}\), a column vector of 0’s, with a variance \(\sigma^2_{\epsilon}\mathbf{I}\), where \(\mathbf{I}\) is the identity matrix.
The variance of the error terms \(\boldsymbol{\epsilon}\) is \[\sigma^2_{\epsilon}\mathbf{I} = \sigma^2_{\epsilon} \begin{bmatrix} 1 & 0 & \dots & 0 \\ 0 & 1 &\dots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \dots & 1 \\ \end{bmatrix} = \begin{bmatrix} \sigma^2_{\epsilon} & 0 & \dots & 0 \\ 0 & \sigma^2_{\epsilon} &\dots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \dots & \sigma^2_{\epsilon} \\ \end{bmatrix}\]
This is the matrix notation showing that the error terms are independent and have the same variance \(\sigma^2_{\epsilon}\).
Based on Equation A.12, the equation for the vector of estimated response values, \(\hat{\mathbf{y}}\), is
\[ \hat{\mathbf{y}} = \mathbf{X}\boldsymbol{\beta} \]
A.3 Estimating the Coefficients
A.3.1 Least-squares estimation
In matrix notation, the error terms can be written as \[ \boldsymbol{\epsilon} = \mathbf{y} - \mathbf{X}\boldsymbol{\beta} \tag{A.14}\]
As with simple linear regression in Section A.1, the least-squares estimator of the vector of coefficients, \(\hat{\boldsymbol{\beta}}\), is the vector that minimizes the sum of squared residuals in Equation A.15. \[ SSR = \sum\limits_{i=1}^{n} \epsilon_{i}^2 = \boldsymbol{\epsilon}^\mathsf{T}\boldsymbol{\epsilon} = (\mathbf{Y} - \mathbf{X}\boldsymbol{\beta})^\mathsf{T}(\mathbf{Y} - \mathbf{X}\boldsymbol{\beta}) \tag{A.15}\]
where \(\boldsymbol{\epsilon}^\mathsf{T}\), the transpose of the vector \(\boldsymbol{\epsilon}\).
Let’s walk through the steps to minimize Equation A.15. We start by expanding the equation.
\[ \begin{aligned} SSR &= (\mathbf{Y} - \mathbf{X}\boldsymbol{\beta})^\mathsf{T}(\mathbf{Y} - \mathbf{X}\boldsymbol{\beta})\\[10pt] & = (\mathbf{Y}^\mathsf{T}\mathbf{Y} - \mathbf{Y}^\mathsf{T} \mathbf{X}\boldsymbol{\beta} - \boldsymbol{\beta}^\mathsf{T}\mathbf{X}^\mathsf{T}\mathbf{Y} +\boldsymbol{\beta}^\mathsf{T}\mathbf{X}^\mathsf{T}\mathbf{X}\boldsymbol{\beta}) \end{aligned} \tag{A.16}\]
Note that \((\mathbf{Y^\mathsf{T}}\mathbf{X}\boldsymbol{\beta})^\mathsf{T} = \boldsymbol{\beta}^\mathsf{T}\mathbf{X}^\mathsf{T}\mathbf{Y}\). These are both constants (i.e. \(1\times 1\) vectors), so we have\(\mathbf{Y^\mathsf{T}}\mathbf{X}\boldsymbol{\beta} = (\mathbf{Y^\mathsf{T}}\mathbf{X}\boldsymbol{\beta})^\mathsf{T}= \boldsymbol{\beta}^\mathsf{T}\mathbf{X}^\mathsf{T}\mathbf{Y}\). Plugging this equality into Equation A.16, we have
\[ SSR = \mathbf{Y}^\mathsf{T}\mathbf{Y} - 2 \boldsymbol{\beta}^\mathsf{T}\mathbf{X}^\mathsf{T}\mathbf{Y} + \boldsymbol{\beta}^\mathsf{T}\mathbf{X}^\mathsf{T}\mathbf{X}\boldsymbol{\beta} \tag{A.17}\]
Next, we find the partial derivative of Equation A.17 with respect to \(\boldsymbol{\beta}\).
Let \(\mathbf{x} = \begin{bmatrix}x_1 & x_2 & \dots & x_p\end{bmatrix}^\mathsf{T}\)be a \(k \times 1\) vector and \(f(\mathbf{x})\) be a function of \(\mathbf{x}\).
Then \(\nabla_\mathbf{x}f\), the gradient of \(f\) with respect to \(\mathbf{x}\) is
\[\nabla_\mathbf{x}f = \begin{bmatrix}\frac{\partial f}{\partial x_1} & \frac{\partial f}{\partial x_2} & \dots & \frac{\partial f}{\partial x_p}\end{bmatrix}^\mathsf{T} \]
Property 1
Let \(\mathbf{x}\) be a \(k \times 1\) vector and \(\mathbf{z}\) be a \(k \times 1\) vector, such that \(\mathbf{z}\) is not a function of \(\mathbf{x}\) . The gradient of \(\mathbf{x}^\mathsf{T}\mathbf{z}\) with respect to \(\mathbf{x}\) is
\[\nabla_\mathbf{x} \hspace{1mm} \mathbf{x}^\mathsf{T}\mathbf{z} = \mathbf{z}\]
Property 2
Let \(\mathbf{x}\) be a \(k \times 1\) vector and \(\mathbf{A}\) be a \(k \times k\) matrix, such that \(\mathbf{A}\) is not a function of \(\mathbf{x}\) . The gradient of \(\mathbf{x}^\mathsf{T}\mathbf{A}\mathbf{x}\) with respect to \(\mathbf{x}\) is
\[ \nabla_\mathbf{x} \hspace{1mm} \mathbf{x}^\mathsf{T}\mathbf{A}\mathbf{x} = (\mathbf{A}\mathbf{x} + \mathbf{A}^\mathsf{T} \mathbf{x}) = (\mathbf{A} + \mathbf{A}^\mathsf{T})\mathbf{x} \]If \(\mathbf{A}\) is symmetric, then \((\mathbf{A} + \mathbf{A}^\mathsf{T})\mathbf{x} = 2\mathbf{A}\mathbf{x}\)
Using the matrix calculus, the partial derivative of Equation A.17 with respect to \(\boldsymbol{\beta}\) is
\[ \begin{aligned} \frac{\partial SSR}{\partial \boldsymbol{\beta}} &= \frac{\partial}{\partial \boldsymbol\beta}(\mathbf{Y}^\mathsf{T}\mathbf{Y} - 2\boldsymbol{\beta}^\mathsf{T} \mathbf{X}^\mathsf{T}\mathbf{Y} + \boldsymbol{\beta}^\mathsf{T}\mathbf{X}^\mathsf{T}\mathbf{X}\boldsymbol{\beta})\\[10pt] & = -2\mathbf{X}^\mathsf{T}\mathbf{Y} + 2\mathbf{X}^\mathsf{T}\mathbf{X}\boldsymbol{\beta} \end{aligned} \tag{A.18}\]
Note that \(\mathbf{X}^\mathsf{T}\mathbf{X}\) is symmetric.
Thus, the least-squares estimator is the \(\hat{\boldsymbol{\beta}}\) that satisfies
\[ -2\mathbf{X}^\mathsf{T}\mathbf{Y} + 2\mathbf{X}^\mathsf{T}\mathbf{X}\hat{\boldsymbol{\beta}} = \mathbf{0} \tag{A.19}\]
The steps to find this \(\hat{\boldsymbol{\beta}}\) are below. \[ \begin{aligned} &- 2 \mathbf{X}^\mathsf{T}\mathbf{Y} + 2 \mathbf{X}^\mathsf{T}\mathbf{X}\hat{\boldsymbol{\beta}} = 0 \\[10pt] & \Rightarrow 2 \mathbf{X}^\mathsf{T}\mathbf{Y} = 2 \mathbf{X}^\mathsf{T}\mathbf{X}\hat{\boldsymbol{\beta}} \\[10pt]& \Rightarrow \mathbf{X}^\mathsf{T}\mathbf{Y} = \mathbf{X}^\mathsf{T}\mathbf{X}\hat{\boldsymbol{\beta}} \\[10pt]& \Rightarrow (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{Y} = (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{X}\hat{\boldsymbol{\beta}} \\[10pt]& \Rightarrow (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{Y} = \hat{\boldsymbol{\beta}}\end{aligned} \tag{A.20}\]
Similar to Section A.1, we check the second derivative to confirm that we have found a minimum. In matrix representation, the second derivative is the Hessian matrix.
The Hessian matrix, \(\nabla_\mathbf{x}^2f\) is a \(k \times k\) matrix of partial second derivatives
\[ \nabla_{\mathbf{x}}^2f = \begin{bmatrix} \frac{\partial^2f}{\partial x_1^2} & \frac{\partial^2f}{\partial x_1 \partial x_2} & \dots & \frac{\partial^2f}{\partial x_1\partial x_p} \\ \frac{\partial^2f}{\partial\ x_2 \partial x_1} & \frac{\partial^2f}{\partial x_2^2} & \dots & \frac{\partial^2f}{\partial x_2 \partial x_p} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^2f}{\partial x_p\partial x_1} & \frac{\partial^2f}{\partial x_p\partial x_2} & \dots & \frac{\partial^2f}{\partial x_p^2} \end{bmatrix} \]
If the Hessian matrix is…
positive definite, then we found a minimum.
negative definitive, then we found a maximum.
neither, then we found a saddle point.
Thus, the Hessian of Equation A.15 is
\[ \begin{aligned} \frac{\partial^2 SSR}{\partial \boldsymbol{\beta}^2} &= \frac{\partial}{\partial \boldsymbol{\beta}}(-2\mathbf{X}^\mathsf{T}\mathbf{Y} + 2\mathbf{X}^\mathbf{T}\mathbf{X}\boldsymbol{\beta}) \\[10pt] & = 2\mathbf{X}^\mathsf{T}\mathbf{X} \end{aligned} \tag{A.21}\]
Equation A.21 is proportional to \(\mathbf{X}^\mathsf{T}\mathbf{X}\), which is a positive definite matrix. Therefore, we found a minimum.
The least-squares estimator in matrix notation is
\[ \hat{\boldsymbol{\beta}} = (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{Y} \]
A.3.2 Geometry of least-squares regression
In Section A.3.1, we used matrix calculus to find \(\hat{\boldsymbol{\beta}}\), the least-squares estimators of the model coefficients. In this section, we present the geometry of least-squares regression to derive the estimator \(\hat{\boldsymbol{\beta}}\). Figure A.1 is a visualization of the geometric representation of least-squares regression.
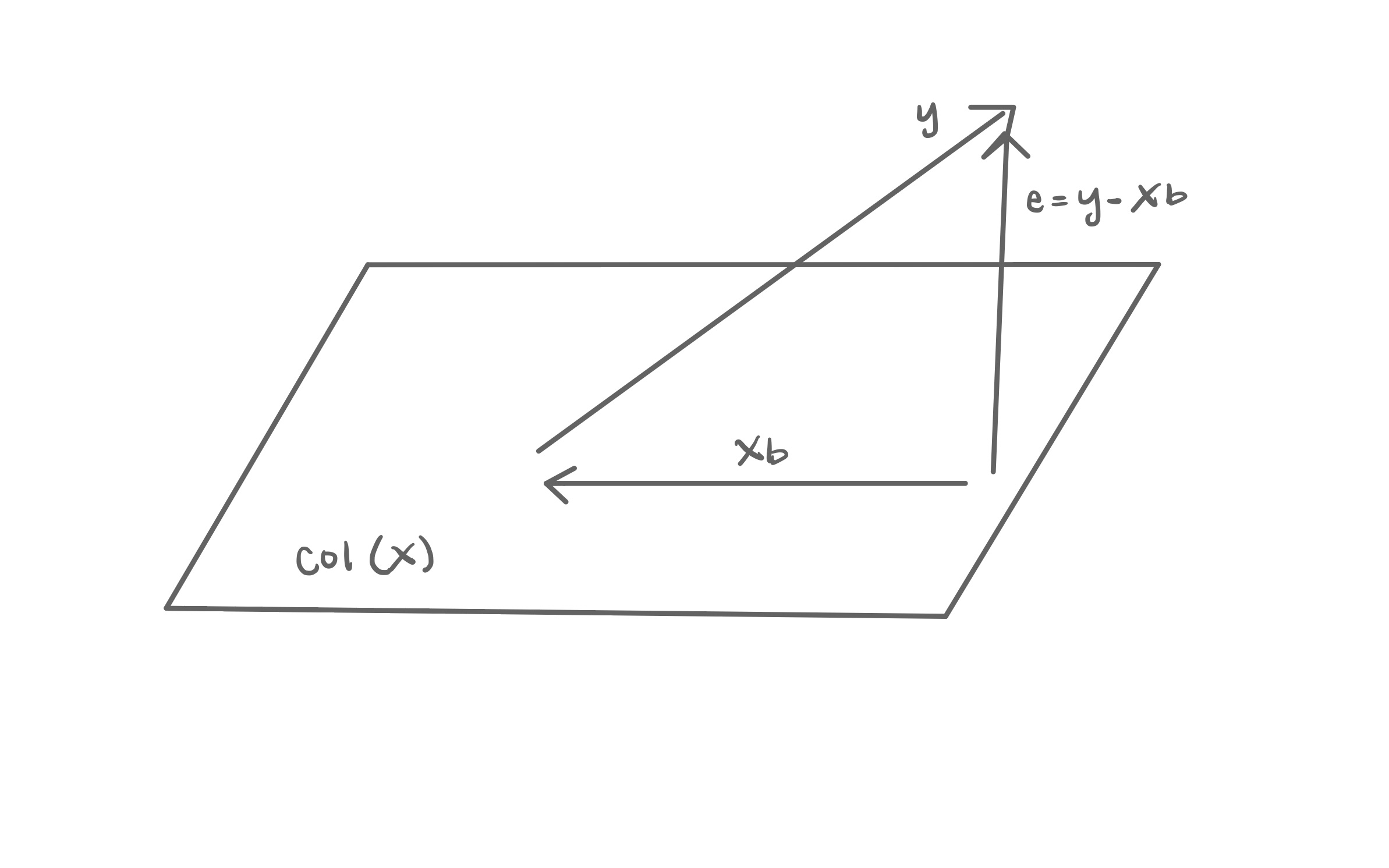
Let \(\text{Col}(\mathbf{X})\) be the column space of the design matrix \(\mathbf{X}\), the set all possible linear combinations of the columns of \(\mathbf{X}\).1 We cannot derive the values of \(\mathbf{y}\) using only linear combinations of \(\mathbf{X}\) (recall the error term \(\boldsymbol{\epsilon}\) in Equation A.12). Therefore, \(\mathbf{y}\) is not in \(\text{Col}(\mathbf{X})\). We want to find another vector \(\mathbf{Xb}\) in \(\text{Col}(\mathbf{X})\) that minimizes the distance to \(\mathbf{y}\). We call the vector \(\mathbf{Xb}\) a projection of \(\mathbf{y}\) onto \(\text{Col}(\mathbf{X})\).
For any vector \(\mathbf{Xb}\) in \(\text{Col}(\mathbf{X})\), the vector \(\mathbf{e} = \mathbf{y} - \mathbf{Xb}\) is the difference between \(\mathbf{y}\) and the projection \(\mathbf{Xb}\). We know \(\mathbf{X}\) and \(\mathbf{y}\) from the data, so we need to find \(\mathbf{b}\) that minimizes the length of \(\mathbf{e} = \mathbf{y} - \mathbf{Xb}\). It is minimized when \(\mathbf{e}\) is orthogonal (also called normal) to \(\text{Col}(\mathbf{X})\).
If \(\mathbf{A}\), an \(n \times k\) matrix, is orthogonal to an \(n \times 1\) vector \(\mathbf{c}\), then \(\mathbf{A}^\mathsf{T}\mathbf{c} = \mathbf{0}\)
Because \(\mathbf{e}\) is orthogonal to \(\text{Col}(\mathbf{X})\), then \(\mathbf{X}^\mathsf{T}\mathbf{e} = \mathbf{0}\). We plug in \(\mathbf{e} = \mathbf{y} - \mathbf{Xb}\) and solve for \(\mathbf{b}\).
\[ \begin{aligned} &\mathbf{X}^\mathsf{T}(\mathbf{y} - \mathbf{Xb}) = \mathbf{0}\\[10pt] \Rightarrow &\mathbf{X}^\mathsf{T}\mathbf{y} - \mathbf{X}^\mathsf{T}\mathbf{X}\mathbf{b} = 0 \\[10pt] \Rightarrow &\mathbf{X}^\mathsf{T}\mathbf{y} = \mathbf{X}^\mathsf{T}\mathbf{X}\mathbf{b}\\[10pt] \Rightarrow &(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{y} = \mathbf{b} \end{aligned} \tag{A.22}\]
Using the geometric interpretation of least-squares regression, we found that the vector \(\mathbf{b}\) that minimizes \(\mathbf{e} = \mathbf{y} - \mathbf{Xb}\) is \(\hat{\mathbf{b}} = (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{y}\). This is equal to the estimator found in Equation A.20.
A.4 Hat matrix
The fitted values of least-squares regression are \(\mathbf{y} = \mathbf{X}\hat{\boldsymbol{\beta}}\). Plugging in \(\hat{\boldsymbol{\beta}}\) from Equation A.20, we have
\[ \hat{\mathbf{y}} = \mathbf{X}\hat{\boldsymbol{\beta}} = \underbrace{\mathbf{X}(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}}_{\mathbf{H}}\mathbf{y} \tag{A.23}\]
From Equation A.23, \(\mathbf{H} = \mathbf{X}(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\) is called the hat matrix. The hat matrix is an \(n \times n\) matrix that maps \(\mathbf{y}\), the vector of observed responses, onto \(\hat{\mathbf{y}}\), the vector of fitted values (\(\hat{\mathbf{y}} = \mathbf{Hy}\)). More precisely, \(\mathbf{H}\) is a projection matrix that projects \(\mathbf{y}\) onto the column space \(\text{Col}(\mathbf{X})\) (see Section A.3.2). Because \(\mathbf{H}\) is a projection matrix, it has the following properties:
\(\mathbf{H}\) is symmetric (\(\mathbf{H}^\mathsf{T} = \mathbf{H}\)).
\(\mathbf{H}\) is idempotent (\(\mathbf{H}^2 = \mathbf{H}\)).
If a vector \(\mathbf{v}\) is in \(\text{Col}(\mathbf{X})\), then \(\mathbf{Hv} = \mathbf{v}\).
If a vector \(\mathbf{v}\) is orthogonal to \(\text{Col}(\mathbf{X})\), then \(\mathbf{Hv}= \mathbf{0}\).
From Equation A.23, the hat matrix only depends on the design matrix \(\mathbf{X}\), i.e., it only depends on the values of the predictors. It does not depend on the vector of responses. The diagonal elements \(\mathbf{H}\) are the values of leverage. More specifically, \(h_{ii}\) is the leverage for the \(i^{th}\) observation. Recall from Section 6.4.2 that in simple linear regression, the leverage is a measure of how far an observation’s value of the predictor is from the average value of the predictor across all observations.
\[ h_{ii} = \frac{1}{n} + \frac{(x_i - \bar{x})^2}{\sum_{j=1}^{n}(x_j-\bar{x})^2} \tag{A.24}\]
In multiple linear regression, the leverage is a measure of how far the \(i^{th}\) observation is from the center of the \(x\) space. It is computed as
\[ h_{ii} = \mathbf{x}_i^\mathsf{T}(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{x}_i \tag{A.25}\]
where \(\mathbf{x}_i^\mathsf{T}\) is the \(i^{th}\) row of the design matrix \(\mathbf{X}\).2
The sum of the leverages for all observation \(p+1\) where \(p\) is the number of predictors in the model. Thus, \(\text{rank}(\mathbf{H}) = \sum_{i=1}^n h_{ii} = p+1\). The average value of leverage is \(\bar{h} = \frac{p+1}{n}\). Observations with leverage greater than \(2\bar{h}\) are considered to have large leverage.
Using \(\mathbf{H}\), we can write the residuals as
\[ \mathbf{e} = \mathbf{y} - \hat{\mathbf{y}} = \mathbf{y} - \mathbf{Hy} = (\mathbf{I} - \mathbf{H})\mathbf{y} \tag{A.26}\]
Equation A.26 shows one feature of observations with large leverage. Observations with large leverage tend to have small residuals. In other words, the model tends to pull towards observations with large leverage.
A.5 Assumptions of linear regression
In Section 5.3, we introduced four assumptions of linear regression. Given the matrix form of the linear regression on model in Equation A.12, \(\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon}\) such that \(\boldsymbol{\epsilon} \sim N(\mathbf{0}, \sigma^2_{\epsilon}\mathbf{I})\) , these assumptions are the following:
- The distribution of the response \(\mathbf{y}\) given \(\mathbf{X}\) is normal.
- The expected value of \(\mathbf{y}\) is \(\mathbf{X}\boldsymbol{\beta}\). There is a linear relationship between the response and predictor variables.
- The variance \(\mathbf{y}\) given \(\mathbf{X}\) is \(\sigma^2_{\epsilon}\mathbf{I}\).
- The error terms in \(\boldsymbol{\epsilon}\) are independent. This also means the observations are independent of one another.
From these assumptions, we write the distribution of \(\mathbf{y}\) given the regression model in Equation A.27.
\[ \mathbf{y}|\mathbf{X} \sim N(\mathbf{X}\boldsymbol{\beta}, \sigma^2_{\epsilon}\mathbf{I}) \tag{A.27}\]
In Section A.2, we showed Assumption 4 from the distribution of the error terms. Here we will show Assumptions 1 - 3.
Suppose \(\mathbf{z}\) is a (multivariate) normal random variable such that \(\mathbf{z} \sim N(\boldsymbol{\mu}, \boldsymbol{\Sigma})\). A linear transformation of \(\mathbf{z}\) is also multivariate normal, such that
\[ \mathbf{A}\mathbf{z} + \mathbf{B} \sim N(\mathbf{A}\boldsymbol{\mu} + \mathbf{B}, \mathbf{A}\boldsymbol{\Sigma}\mathbf{A}^\mathsf{T}) \]
The distribution of the error terms \(\boldsymbol{\epsilon}\) is normal, and the vector of responses \(\mathbf{y}\) is linear combination of the error terms. More specifically, \(\mathbf{y}\) is computed as the error terms, shifted by \(\mathbf{X}\boldsymbol{\beta}\). Thus, from the math property above, we know that \(\mathbf{y}\) is normally distributed.
Expected value of a vector
Let \(\mathbf{z} = \begin{bmatrix}z_1 & \dots & z_p\end{bmatrix}^\mathsf{T}\) be a \(p \times 1\) vector of random variables. Then \(E(\mathbf{z}) = E\begin{bmatrix}z_1 & \dots & z_p\end{bmatrix}^\mathsf{T} = \begin{bmatrix}E(z_1) & \dots & E(z_p)\end{bmatrix}^\mathsf{T}\)
Let \(\mathbf{A}\) be an \(n \times p\) matrix of constants, \(\mathbf{C}\) a \(n \times 1\) vector of random variables, and \(\mathbf{z}\) a \(p \times 1\) vector of random variables. Then
\[ E(\mathbf{Az} + \mathbf{C}) = \mathbf{A}E(\mathbf{z}) +E(\mathbf{C}) \]
Next, let’s show Assumption 2 that the expected value of \(\mathbf{y} = \mathbf{X}\boldsymbol{\beta}\) in linear regression. We can get the expected value of \(\mathbf{y}\) from the mathematical properties above used for Assumption 1. Here, we show Assumption 2 directly from the properties of expected values.
\[ \begin{aligned} E(\mathbf{y}) &= E(\mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon}) \\[10pt] & = E(\mathbf{X}\boldsymbol{\beta}) + E(\boldsymbol{\epsilon})\\[10pt] & = \mathbf{X}\boldsymbol{\beta} + \mathbf{0} \\[10pt] & = \mathbf{X}\boldsymbol{\beta} \end{aligned} \tag{A.28}\]
Let \(\mathbf{z}\) be a \(p \times 1\) vector of random variables. Then
\[ Var(\mathbf{z}) = E[(\mathbf{z} - E(\mathbf{z}))(\mathbf{z} - E(\mathbf{z}))^\mathsf{T}] \]
Lastly, we show Assumption 3 that \(Var(\mathbf{y}) = \sigma^2_{\epsilon}\mathbf{I}\) in linear regression. Similar to the expected value, we can get the variance from the mathematical property used to show Assumption 1. Here, we show Assumption 3 directly from the properties of variance. \[ \begin{aligned} Var(\mathbf{y}) &= E[(\mathbf{y} - E(\mathbf{y}))(\mathbf{y} - E(\mathbf{y}))^\mathsf{T}] \\[10pt] & = E[(\mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon} - \mathbf{X}\boldsymbol{\beta})(\mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon} - \mathbf{X}\boldsymbol{\beta})^\mathsf{T}] \\[10pt] & = E[\boldsymbol{\epsilon}\boldsymbol{\epsilon}^\mathsf{T}] \\[10pt] (\text{given }E(\boldsymbol{\epsilon} = \mathbf{0})) & = E[(\boldsymbol{\epsilon} - E(\boldsymbol{\epsilon}))(\boldsymbol{\epsilon} - E(\boldsymbol{\epsilon}))^\mathsf{T}]\\[10pt] & = Var(\boldsymbol{\epsilon}) \\[10pt] & = \sigma^2_{\epsilon}\mathbf{I} \end{aligned} \tag{A.29}\]
A.6 Distribution of model coefficients
In Section 8.4.1, we introduced the distribution of a model coefficient \(\hat{\beta}_j \sim N(\beta_j, SE_{\hat{\beta}_j}^2)\). In matrix notation, the distribution of all the estimated coefficients \(\hat{\boldsymbol{\beta}}\) is
\[ \hat{\boldsymbol{\beta}} \sim N\Big(\boldsymbol{\beta}, \sigma^2_{\epsilon}(\mathbf{X}^\mathsf{T},\mathbf{X})^{-1}\Big) \tag{A.30}\]
Similar to Section A.5, let’s derive each part of this distribution. We’ll start with \(E(\hat{\boldsymbol{\beta}}) = \boldsymbol{\beta}\).
\[ \begin{aligned} E(\hat{\boldsymbol{\beta}}) &= E((\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{y}) \\[10pt] & = (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}E(\mathbf{y})\\[10pt] & = (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}E(\mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon}) \\[10pt] &=(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}E(\mathbf{X}\boldsymbol{\beta}) + (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}E(\boldsymbol{\epsilon}) \\[10pt] & = (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{X}\boldsymbol{\beta} + \mathbf{0}\\[10pt] &= \boldsymbol{\beta} \end{aligned} \tag{A.31}\]
Next, we show that \(Var(\hat{\boldsymbol{\beta}}) = \sigma^2_{\epsilon}\mathbf{I}\).
\[ \begin{aligned} Var(\hat{\boldsymbol{\beta}}) &= E[(\hat{\boldsymbol{\beta}} - E(\hat{\boldsymbol{\beta}}))(\hat{\boldsymbol{\beta}} - E(\hat{\boldsymbol{\beta}}))^\mathsf{T}] \\[10pt] & = E[((\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{y} - \boldsymbol{\beta})((\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{y} - \boldsymbol{\beta})^\mathsf{T}] \\[10pt] & = E[((\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}(\mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon}) - \boldsymbol{\beta})((\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}(\mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon}) - \boldsymbol{\beta})^\mathsf{T}] \\[10pt] &\dots \text{After distributing and simplifying}\dots \\[10pt] & = E[(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\boldsymbol{\epsilon}\boldsymbol{\epsilon}^\mathsf{T}\mathbf{X}(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}] \\[10pt] & = (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\underbrace{E(\boldsymbol{\epsilon}\boldsymbol{\epsilon}^\mathsf{T})}_{\sigma^2_{\epsilon}\mathbf{I}}\mathbf{X}(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\\[10pt] &= \sigma^2\mathbf{I}(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{X}(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\\[10pt] & = \sigma^2_{\epsilon}(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1} \end{aligned} \tag{A.32}\]
Lastly, we show that the distribution of \(\boldsymbol{\beta}\) is normal. We’ll start by rewriting \(\hat{\boldsymbol{\beta}}\) in terms of \(\boldsymbol{\beta}\).
\[ \begin{aligned} \hat{\boldsymbol{\beta}} &= (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{y} \\[10pt] & = (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}(\mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon}) \\ & = \boldsymbol{\beta} + (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\boldsymbol{\epsilon} \end{aligned} \tag{A.33}\]
From Equation A.33, we see that \(\hat{\boldsymbol{\beta}}\) is a linear combination of the error terms \(\boldsymbol{\epsilon}\). From the math property in Section A.5, because \(\boldsymbol{\epsilon}\) is normally distributed, the linear combination is also normally distributed. Thus, the distribution of the coefficients \(\hat{\boldsymbol{\beta}}\) is normal.
A.7 Multicollinearity
Recall the design matrix for a linear regression model with \(p\) predictors in Equation A.13
\[ \mathbf{X} = \begin{bmatrix} 1 &x_{11} & \dots & x_{1p}\\ \vdots & \vdots &\ddots & \vdots \\ 1 & x_{n1} & \dots &x_{np} \end{bmatrix} \tag{A.34}\]
The design matrix \(\mathbf{X}\) has full column rank \(\text{rank}(\mathbf{X}) = (p + 1)\) in linear regression. This means there are no linear dependencies among the columns, and thus no column is a perfect linear combination of the others. The equation for the least-squares estimator \(\hat{\boldsymbol{\beta}}\) in Equation A.20 includes the term \((\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\). If \(\mathbf{X}\) is not full rank, then \(\mathbf{X}^\mathsf{T}\mathbf{X}\) is not full rank, and is therefore singular (not invertible). Thus, if there are linear dependencies in \(\mathbf{X}\), we are unable to compute an the least-squares estimator \(\hat{\boldsymbol{\beta}}\).
Let \(\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_p\) be a sequence of vectors. Then, \(\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_p\) are linearly dependent, if there exists scalars \(a_1, a_2, \ldots, a_p\) such that
\[ a_1\mathbf{x}_1 + a_2\mathbf{x}_2 + \dots + a_p\mathbf{x}_p = \mathbf{0} \]
where \(a_1, a_2, \ldots, a_p\) are not all 0.
In practice, we rarely have perfect linear dependencies. In fact, this is mathematically why we only include \(k-1\) terms in the model for a categorical predictor with \(k\) levels. Ideally the columns of \(\mathbf{X}\) would be orthogonal, indicating the predictors are completely independent on one another. In practice, we expect there to be some dependence between predictors (we see this from the non-zero off diagonals in \(Var(\hat{\boldsymbol{\beta}})\)). If two or more variables are highly correlated, then there will be near linear dependence in the columns. This near-linear dependence is called multicollinearity.
In Section 8.6 we discussed the practical issues that come from the presence of multicollinearity. These primarily stem from the fact that when there is multicollinearity, \(\mathbf{X}^\mathsf{T}\mathbf{X}\) is near-singular (almost a singular matrix) to a, thus making \((\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\) very large and unstable. Consequently, \(Var(\hat{\boldsymbol{\beta}})\) is then large and unstable, thus making hard to find stable values for the least-squares estimators.
A.8 Maximum Likelihood Estimation
In Section 10.2.3, we introduced the likelihood function to understand the model performance statistics AIC and BIC. We also used a likelihood function to estimate the coefficients in logistic regression (more on this in Appendix B). The likelihood function is a measure of how likely it is we observe our data given particular value(s) of model parameters. When working with likelihood functions, we have fixed data (our observed sample data) and we can try out different values for the model parameters (\(\boldsymbol{\beta}\) and \(\sigma^2_{\epsilon}\) in the context of regression).3
Let \(\mathbf{z}\) be a \(p \times 1\) vector of random variables, such that \(\mathbf{z}\) follows a multivariate normal distribution with mean \(\boldsymbol{\mu}\) and variance \(\boldsymbol{\Sigma}\). Then the probability density function of \(\mathbf{z}\) is
\[f(\mathbf{z}) = \frac{1}{(2\pi)^{p/2}|\boldsymbol{\Sigma}|^{1/2}}\exp\Big\{-\frac{1}{2}(\mathbf{z} - \boldsymbol{\mu})^\mathsf{T}\boldsymbol{\Sigma}^{-1}(\mathbf{z}- \boldsymbol{\mu})\Big\}\]
In Section A.5, we showed that the vector of responses \(\mathbf{y}\) can be written as \(\mathbf{y}|\mathbf{X} \sim N(\mathbf{X}\boldsymbol{\beta}, \sigma^2_{\epsilon}\mathbf{I})\). Using this distribution to describe the relationship between the response and predictor variables, the likelihood function for the regression parameters \(\boldsymbol{\beta}\) and \(\sigma^2_{\epsilon}\) is
\[ L(\boldsymbol{\beta}, \sigma^2_{\epsilon} | \mathbf{X}, \mathbf{y}) = \frac{1}{(2\pi)^{n/2}\sigma^n_{\epsilon}}\exp\Big\{-\frac{1}{2\sigma^2_{\epsilon}}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^\mathsf{T}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta})\Big\} \tag{A.35}\]
where \(n\) is the number of observations, the mean is \(\mathbf{X}\boldsymbol{\beta}\) and the variance is \(\sigma^2_{\epsilon}\mathbf{I}\).
The data \(\mathbf{y}\) and \(\mathbf{X}\) are fixed (we use the same sample data in the analysis!), so we can plug in values for \(\boldsymbol{\beta}\) and \(\sigma^2_{\epsilon}\) to determine the likelihood of obtaining those values for the parameters given the observed data. In Section A.3.1, we used least-squares estimation (minimizing \(SSR\) ) find the estimated coefficients \(\hat{\boldsymbol{\beta}}\). Another approach to estimate \(\boldsymbol{\beta}\) (and \(\sigma^2_{\epsilon}\)) is to find \(\hat{\boldsymbol{\beta}}\) (and \(\hat{\sigma}^2_{\epsilon}\)) that maximizes the likelihood function in Equation A.35. This is called maximum likelihood estimation.
To make the calculations more manageable, instead of maximizing the likelihood function, we will instead maximize its logarithm, i.e. the log-likelihood function. The values of the parameters that maximize the log-likelihood function are those that maximize the likelihood function. The log-likelihood function is
\[ \begin{aligned}\log L(\boldsymbol{\beta}, \sigma^2_\epsilon &| \mathbf{X}, \mathbf{y}) \\ & = -\frac{n}{2}\log(2\pi) - n \log(\sigma_{\epsilon}) - \frac{1}{2\sigma^2_{\epsilon}}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^\mathsf{T}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta})\end{aligned} \tag{A.36}\]
Given a fixed value of \(\sigma^2_{\epsilon}\), the log-likelihood in Equation A.36 is maximized when \((\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^\mathsf{T}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta})\) is minimized. This is equivalent to minimizing the \(SSR\) in Equation A.15. Thus, the least-squares estimator of \(\boldsymbol{\beta}\) is also the maximum likelihood estimator ( \(\hat{\beta} = (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{y}\)) when the error terms are defined as in Equation A.12.
We previously found \(\hat{\boldsymbol{\beta}}\) using least-squares estimation and the geometry of regression in Section A.3.1, so why does it matter that \(\hat{\boldsymbol{\beta}}\) is also the maximum likelihood estimator? First, maximum likelihood estimation is used to find the coefficients for generalized linear models and many other statistical models that go beyond linear regression (we’ll see how its used for logistic regression in Appendix B). In fact, Casella and Berger (2024) stated maximum likelihood estimation is “by far, the most popular technique for deriving estimators.” [pp. 315]. Second, maximum likelihood estimators have nice statistical properties. These properties are beyond the scope of this text, but we refer interested readers to Chapter 7 of Casella and Berger (2024) for an in-depth discussion of maximum likelihood estimators and their properties.
A.9 Variable transformations
In Chapter 9, we introduced regression models with transformations on the response and/or predictor variables. Here we will share some of the mathematical details behind the interpretation of the coefficients in these models.
A.9.1 Transformation on the response variable
In Section 9.2, we introduced a linear regression model with a log transformation on the response variable
\[ \log(Y) = \beta_0 + \beta_1X_1 + \dots + \beta_pX_p + \epsilon \tag{A.37}\]
In this text, \(\log(a)\) is the natural log of \(a\) (also denoted as \(\ln(a)\)).
\(\log(a) + \log(b) = \log(ab)\).
\(\log(a) - \log(b) = \log(\frac{a}{b})\)
\(e^{\log(a)} = a\)
\(e^{b\log(a)} = a^b\)
From Chapter 7, we have that the change in \(\log(Y)\) when \(X_j\) increase by 1 unit is \(\beta_j\). Thus \(\beta_j = \log(Y|{X_j+1}) - \log(Y|X_j)\), where \(Y|X_{j}+1\) is the value of \(Y\) when we plug in \(X_j+1\) and \(Y|{X_j}\) is the value of \(Y\) when we plug in \(X_j\). In practice, we interpret the model coefficients \(\beta_j\) in terms of the original variable \(Y\), so we can use the rules of logarithms and exponents to rewrite this in terms of the original units of the response variable.
\[ \begin{aligned} \beta_j &= \log(Y|X_j+1) - \log(Y|X_j) \\[10pt] & = \log\Big(\frac{Y|X_j+1}{Y|X_j}\Big) \\[10pt] \Rightarrow \beta_j \times Y|X_j &= Y|X_j+1 \end{aligned} \]
Thus given the model in Equation A.37, when \(X_j\) increases by 1 unit, we expect \(Y\) to multiply by \(\beta_j\), assuming all other predictors are held constant.
A.9.2 Transformation on predictor variable(s)
Next, we consider the models introduced in Section 9.3 that have a log transformation on a predictor variable.
\[ Y = \beta_0 + \beta_1X_1 + \dots + \beta_j\log(X_j) + \dots + \beta_pX_p + \epsilon \tag{A.38}\]
Now, we because the predictor \(X_j\) has been transformed to the logarithmic scale, we write interpretations in terms of a multiplicative change in \(X_j\). More specifically, given a constant \(C\), \(\log(CX_j) = \log(C) + \log(X_j)\). Let \(Y|CX_j\) be the expected value of \(Y\) when we plug in \(CX_j\) and \(Y|X_j\) be the expected value of \(Y\) when we plug in \(X_j\). Assuming all other predictors held constant, we have
\[ \begin{aligned} Y|CX_j - Y|CX &= \beta_j\log(CX_j) - \beta_j\log(X_j) \\ & = \beta_j[\log(CX_j) - \log(X_j) \\ & = \beta_j[\log(C) + \log(X_j) - \log(X_j)] \\ &= \beta_j\log(C) \\[10pt] \Rightarrow Y|CX_j &=Y|X_j + \beta_j\log(C) \end{aligned} \]
Thus, given the model in Equation A.38, when predictor \(X_j\) is multiplied by a constant \(C\), we expect \(Y\) to change (increase or decrease) by \(\beta_j\log(C)\), holding all other predictors constant.
A.9.3 Transformation on response and predictor variables
Lastly, we show the mathematics behind the interpretation of a model coefficient \(\beta_j\) for the linear regression models introduced in Section 9.4 with a log transformation on the response variable and a predictor variable. As in Section A.9.1, we want to write the interpretation in terms of the original response variable \(Y\).
\[ \log(Y) = \beta_0 + \beta_1X_1 + \dots + \beta_j\log(X_j) + \dots + \beta_pX_p \tag{A.39}\]
Combining the results from Section A.9.1 and Section A.9.2 and holding all other predictors constant, we have
\[ \begin{aligned} \log(Y|CX_j) -\log(Y|X_j) &= \beta_j\log(C)\\[10pt] \log\Big(\frac{Y|CX_j}{Y|X_j}\Big) &= \beta_j\log(C) \\[10pt] \frac{Y|CX_j}{Y|X_j} &= C^{\beta_j} \\[10pt] \Rightarrow Y|CX_j &= Y|X_jC^{\beta_j} \end{aligned} \tag{A.40}\]
Therefore, given the model in Equation A.39 with a transformed response variable and transformed predictor, when \(X_j\) is multiplied by a constant \(C\), why is expected to multiply by \(C^{\beta_j}\), holding all other predictors constant.
This is the span of \(\mathbf{X}\).↩︎
Note that when there is a single predictor, Equation A.24 and Equation A.25 produce the same result.↩︎
Note that the likelihood function is not the same as a probability function. In a probability function, we fix the model parameters and plug in different values for the data.↩︎