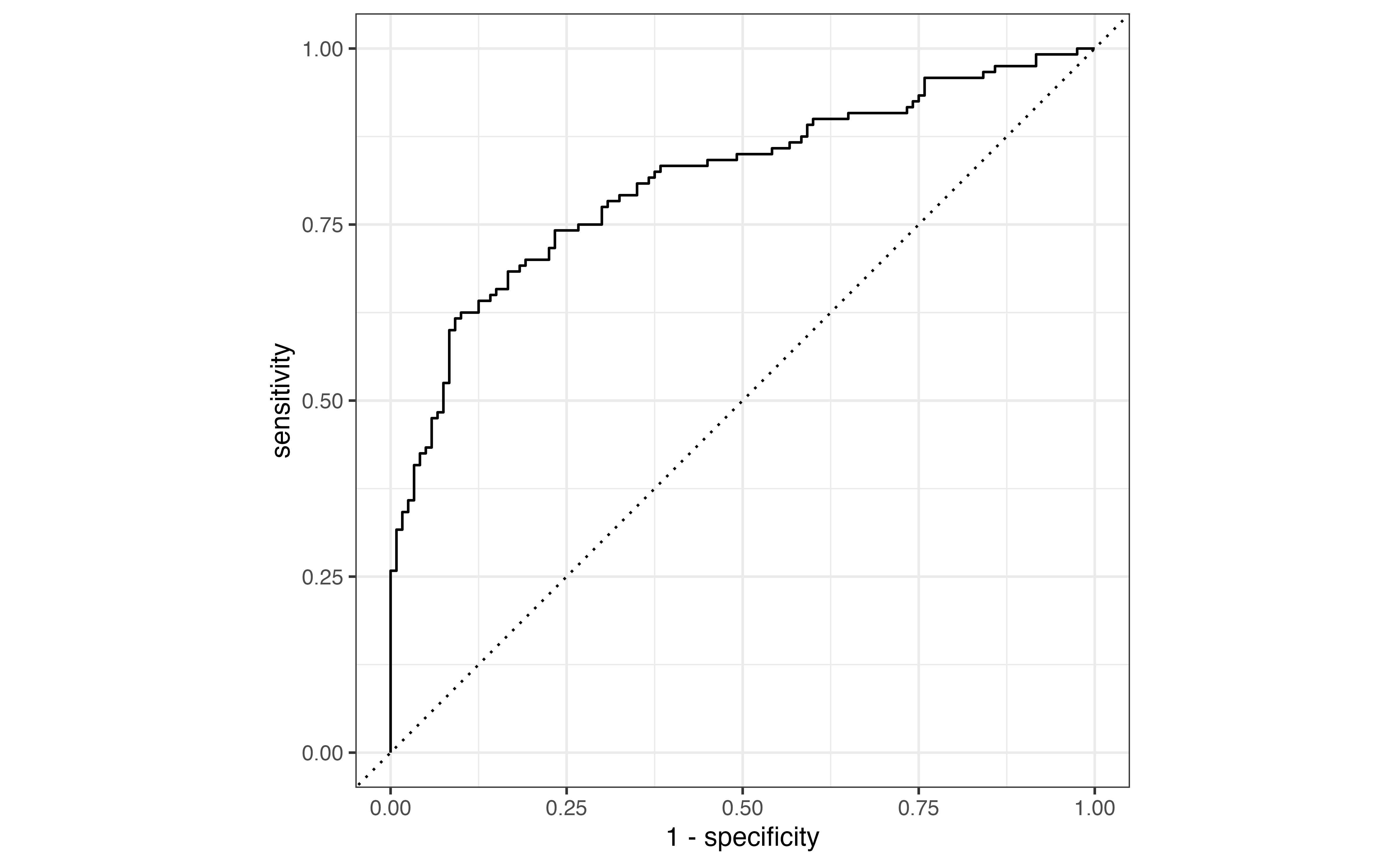
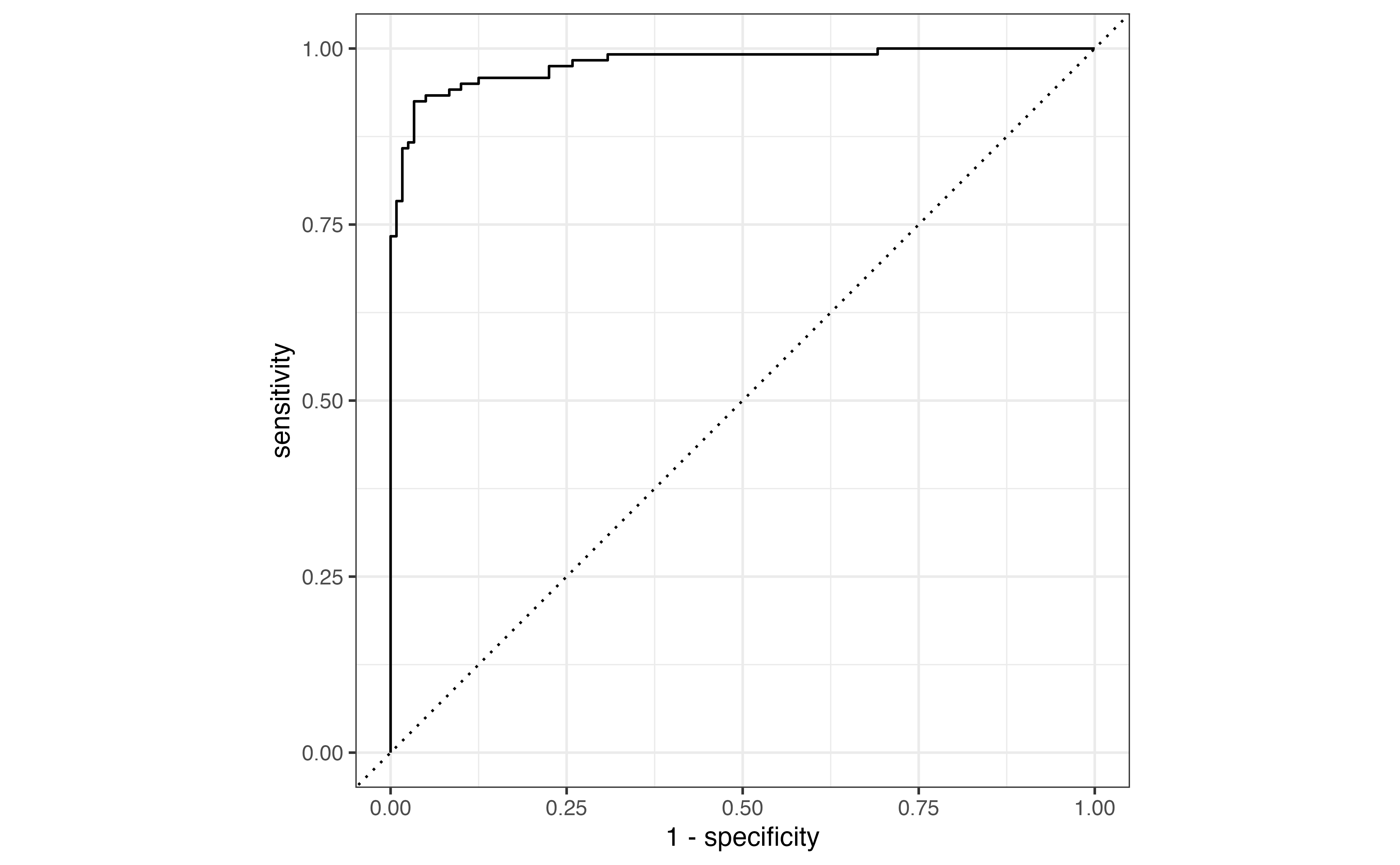
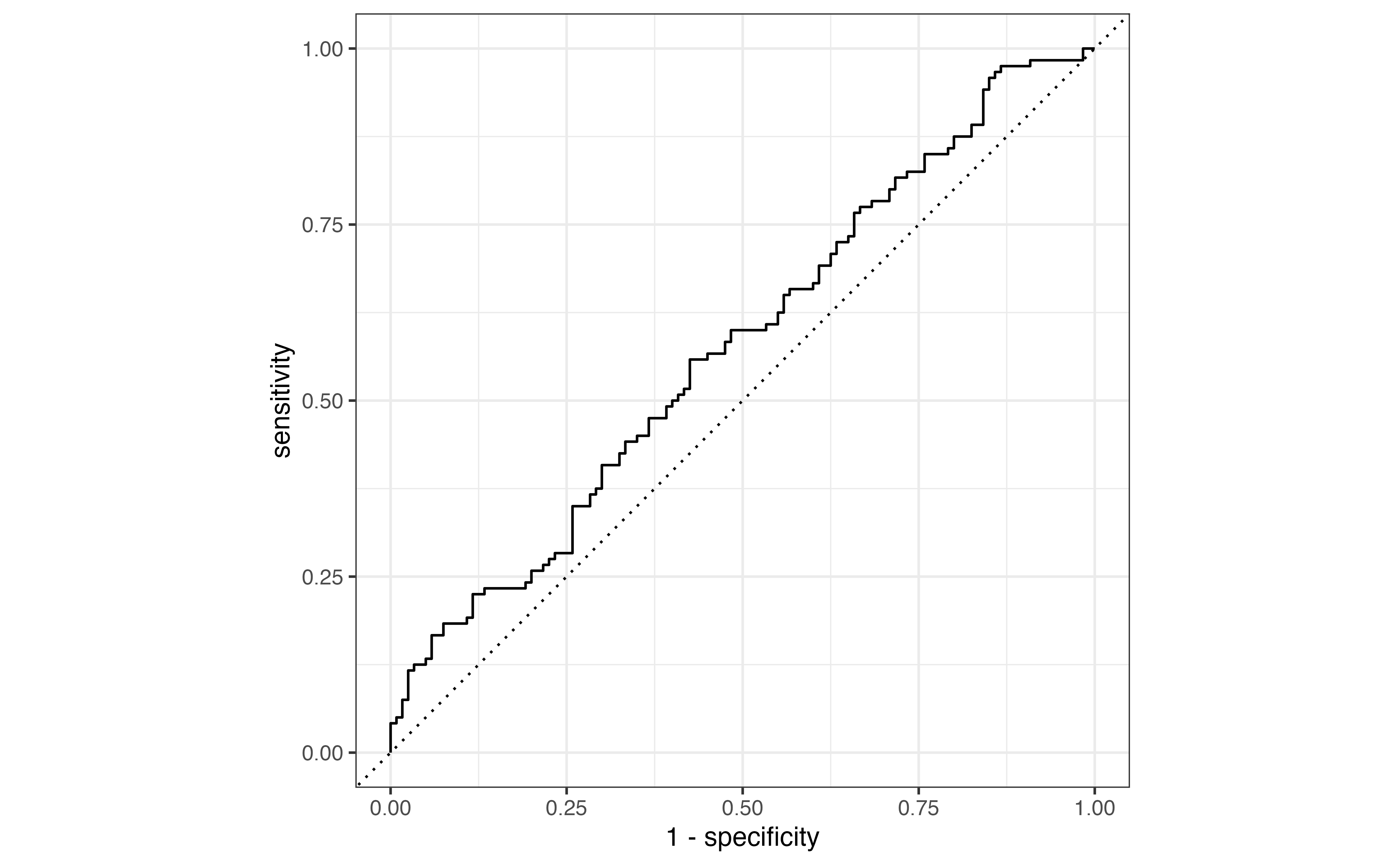
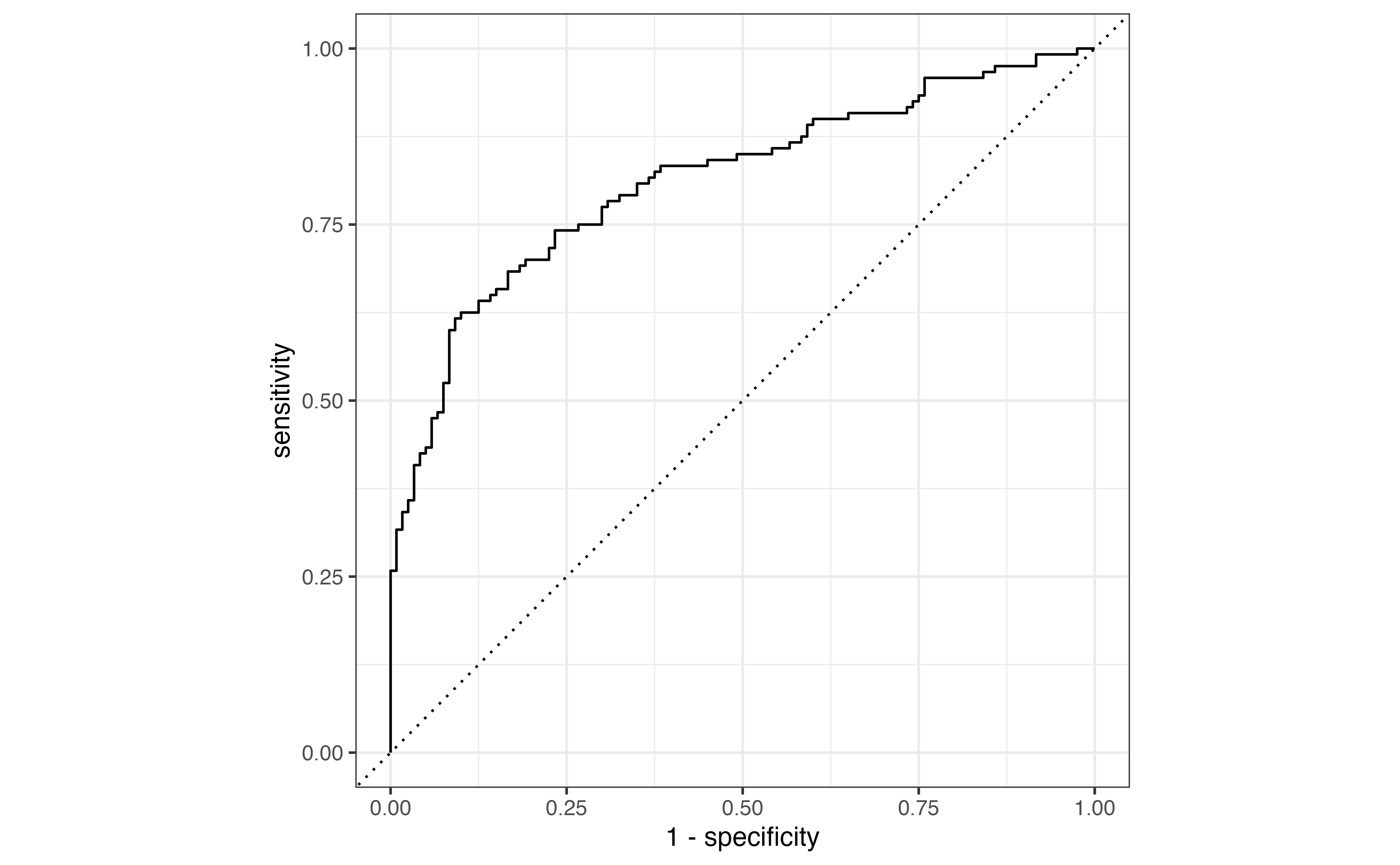
Prediction
Recall from Section 11.3 that the response variable in the logistic regression model is the logit (log-odds). When we input values of age, tech_easy, and income into the model in Table 12.1, the model will output the log odds an individual with those characteristics is comfortable with driverless cars. Once we have the predicted log odds, we can use the relationships in Section 11.2 to compute the predicted odds and the predicted probability. Table 12.2 shows the predicted log odds, predicted odds, and predicted probability for 10 observations in the data set.
Let’s show how the predicted values for the first observation are computed. The predicted log odds the first individual who is 33 years old, agrees that technology makes life better, and has an annual income of $110k or more are
\[
\begin{aligned}
\log \Big(\frac{\hat{\pi}}{1-\hat{\pi}}\Big) &= 0.032 - 0.016 \times 33 + 0.075 \times 0 + 0.576 \times 1 \\
&- 0.436 \times 0 + 0.264 \times 0 + 0.526 \times 0 \\
& + 1.223 \times 1 + 0.265 \times 0 \\
& = 1.3
\end{aligned}
\]
where \(\hat{\pi}\) is the predicted probability of being comfortable with driverless cars.
Using the predicted log odds from Table 12.2, the predicted odds for this individual are
\[\widehat{\text{odds}} = e^{\log \big( \frac{\hat{\pi}}{1-\hat{\pi}}\big)} = e^{1.306} = 3.69 \]
Lastly, we use the odds from Table 12.2 to compute the predicted probability:
\[
\hat{\pi} = \frac{\widehat{\text{odds}}}{1 + \widehat{\text{odds}}} = \frac{3.692}{1 + 3.692} = 0.787
\]
Note: These values may differ slightly from the values in the the table, because we are computing predictions using rounded coefficient.
Show how to compute the predicted log odds, odds, and probability for individual #2 in Table 12.2.
Classification
Knowing the predicted odds and probabilities can be useful for understanding how likely individuals with various characteristics will be comfortable with driverless cars. In many contexts, however, we would like to group individuals based on whether or not the model predicts they are comfortable with driverless cars. For example, the marketing team for a robotaxi company may want to use targeted marketing strategies and offer discounts to potential new customers. To have a successful marketing campaign, they want to direct the marketing to those who are comfortable with driverless cars.
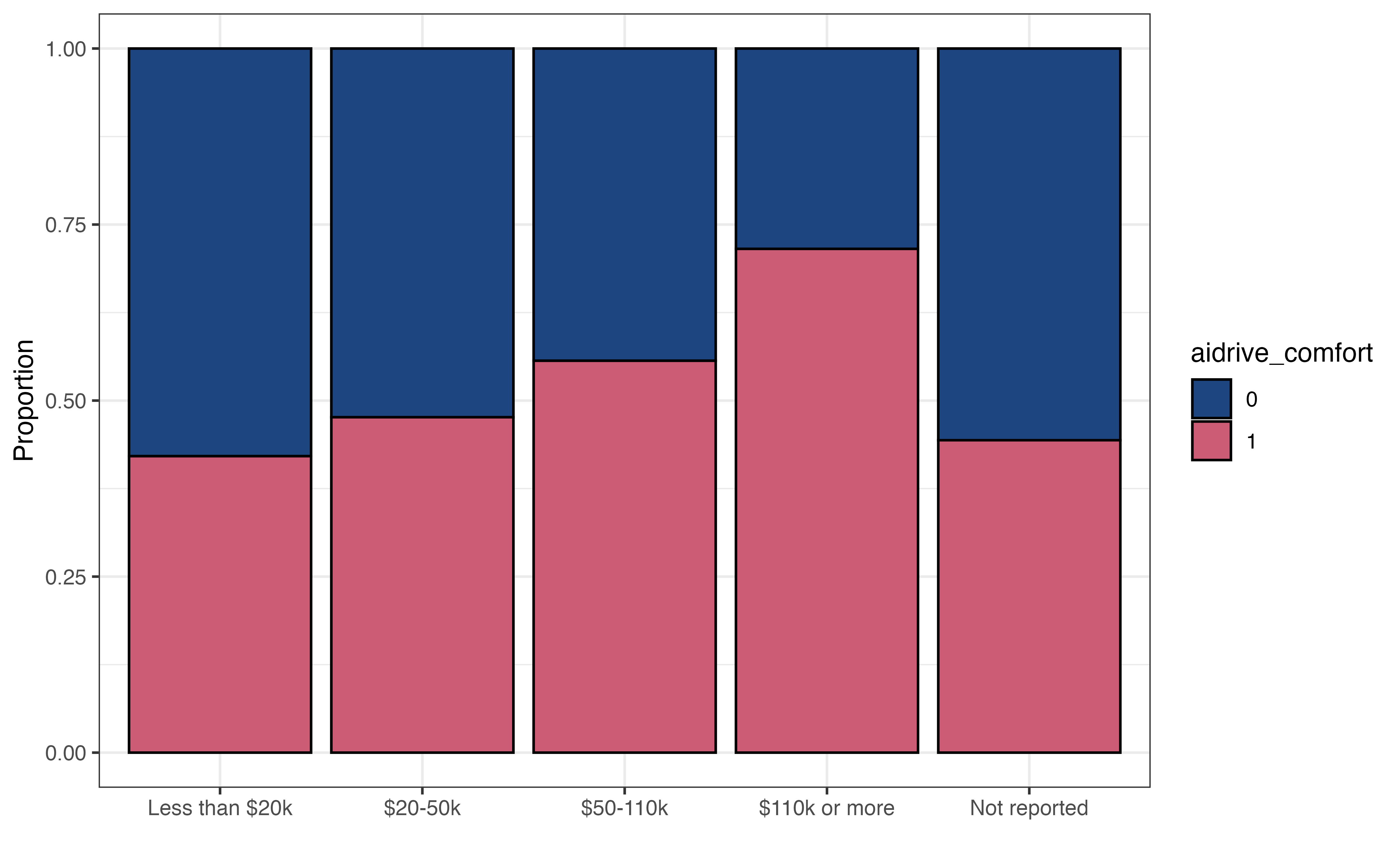
As we’ve seen thus far, the logistic regression model does not directly produce predicted values of the binary response variable. Therefore, we can group observations based on the predicted probabilities computed from the model output. This process of grouping observations based on the predictions is called classification. The groups the observations are put into are the predicted classes. In the case of our analysis, we will use the model to classify observations into the class of those not comfortable with driverless cars (aidrive_comfort = 0) or the class of those comfortable with driverless cars (aidrive_comfort = 1) .
We showed how to compute the predicted probabilities from the logistic regression output in Section 12.3.1, and we will use those probabilities to classify observations. The question, then, is how large does the probability need to be to classify an observation as having the response \(Y = 1\) ? In terms of our analysis, how large does the probability of being comfortable with driverless cars need to be to classify an individual as being comfortable with driverless cars, aidrive_comfort = 1?
When using the logistic regression model for classification, we define a threshold, such an observation is classified as \(\hat{Y} = 1\) if the predicted probability is greater than the threshold. Otherwise, the observation is classified as \(\hat{Y} = 0\). If we’re unsure what threshold to set, we can start with a threshold of 0.5, the default threshold typically used in statistical software. This means if the model predicts an observation is more likely than not to have response \(Y = 1\), even if just by a small amount, then the observation is classified as having response \(\hat{Y} = 1\).
For now, let’s use the threshold equal to 0.5 to assign the predicted classes of aidrive_comfort for the respondents in the sample data based on the predicted probabilities produced from the model in Table 12.1.
Table 12.3 shows the observed value of the response (aidrive_comfort), predicted probability, and predicted class for ten respondents. For many of these respondents, the observed and predicted classes are equal. There are some, such as Observation 6, in which the predicted classes differs from the observed. In this instance, the respondent had a combination of age, income, and tech_easy, that are associated with a higher probability of being comfortable with driverless cars; however, the individual responded they are not comfortable with driverless cars in the General Social Survey.
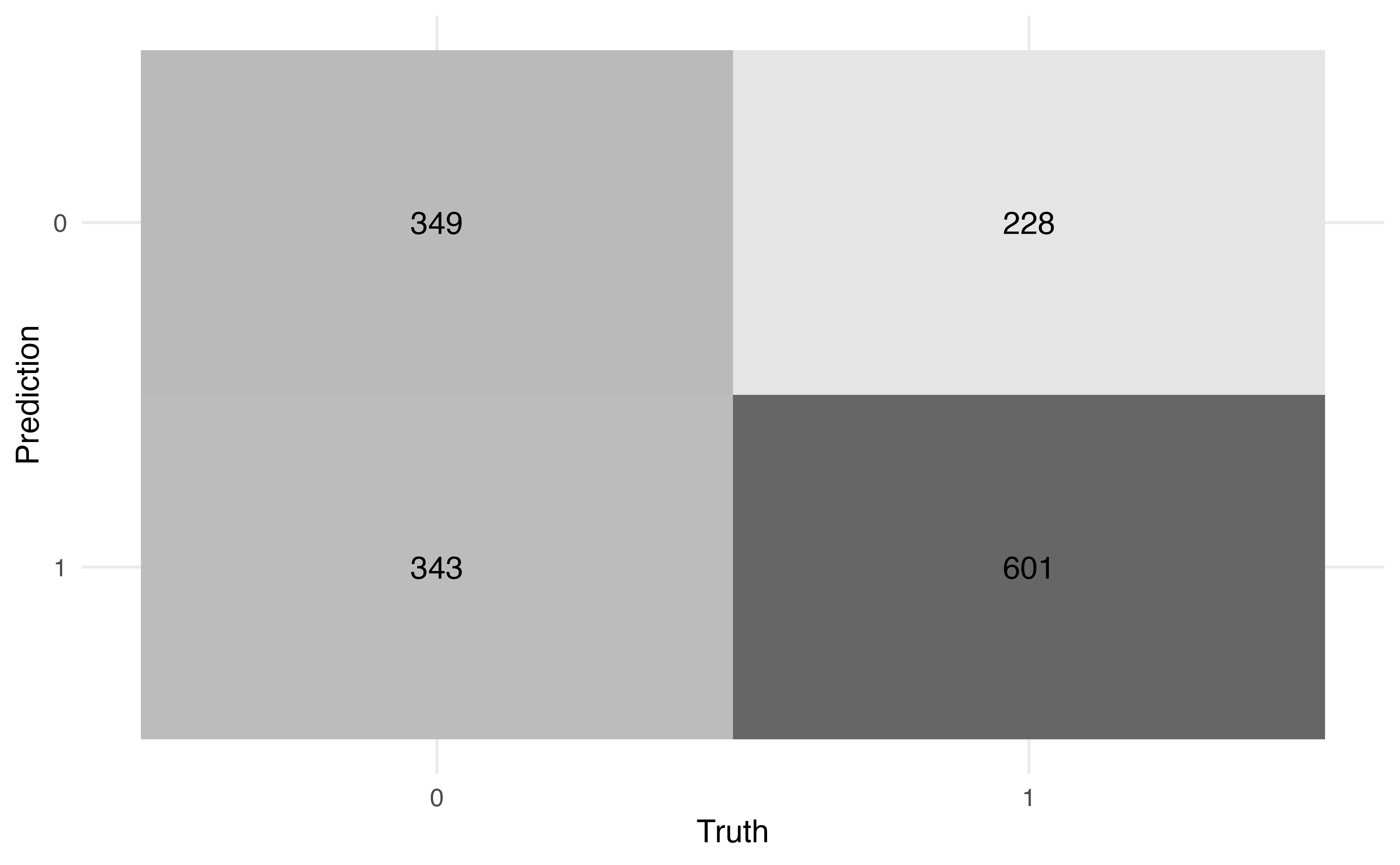
We need a way to more holistically evaluate how well the predicted classes align with the observed classes. To do so, we use a confusion matrix, a \(2 \times 2\) table of the observed classes versus the predicted classes.
Table 12.4 shows the confusion matrix for the model in Table 12.1 and a threshold of 0.5. In this table, the rows define the predicted classes and the columns define the observed classes. Let’s break down what each cell is in the table:
- There are 349 observations with the predicted class of 0 and observed class of 0.
- There are 228 observations with the predicted class of 0 and observed class of 1.
- There are 343 observations with the predicted class of 1 and observed class of 0.
- There are 601 observations with the predicted class of 1 and observed class of 1.
We compute various statistics from the confusion matrix to evaluate how well the observations are classified. The first statistics we can calculate are the accuracy and misclassification rate. The accuracy is the proportion of observations that are correctly classified (the observed and predicted classes are the same). The accuracy based on Table 12.4 is
\[
\text{accuracy} = \frac{349 + 601}{349 + 228 + 343 + 601} = 0.625
\tag{12.1}\]
Using the model in Table 12.1 and the threshold of 0.5, 62.5% of the observations are correctly classified.
The misclassification rate is the proportion of observations that are not correctly classified (the observed and predicted classes differ). The misclassification rate based on Table 12.4 is
\[
\text{misclassification} = \frac{228 + 343}{349 + 228 + 343 + 601} = 0.375
\tag{12.2}\]
Using the model in Table 12.1 and the threshold of 0.5, 37.5% of the observations are incorrectly classified. Note that the misclassification rate is equal to \(1 - \text{accuracy}\) ,and vice versa.
When the distribution of the response variable is largely imbalanced, the accuracy can be a misleading measure of how well the observations are classified. For example, suppose there are 100 observations, such that 5% of the observations have an observed response \(Y = 1\), and 95% of the observations have an observed response of \(Y = 0\). We may observe an imbalanced distribution like this when building a model to detect the presence of a rare disease, for example.
Let’s suppose based on the model and threshold, all observations have a predicted class of 0, and the confusion matrix looks like the following:
| Pred. class |
0 |
1 |
| 0 |
95 |
5 |
| 1 |
0 |
0 |
The accuracy for this model will be (95 + 0 ) / (95 + 5) = 0.95. Based on this value, it appears the classification has performed very well, even though we did not accurately classify any of the observations in which the observed response is \(Y = 1\).
The accuracy and misclassification rate provide a nice initial indication of the how well the model classifies observations, but they do not give a complete picture. For example, suppose we want to know how many of the people who are actually comfortable with driverless cars are predicted to be comfortable based on the model predictions and threshold. Or suppose we want to know how many people who are actually not comfortable with driverless cars were incorrectly classified as being comfortable. To answer these and similar questions, let’s take a more detailed look at the confusion matrix.
Table 12.5 shows in greater detail what is being quantified in each cell of the confusion matrix. We will use these values to compute more granular values about the classification. As in Table 12.4, the rows define the predicted classes and the columns define the observed classes. The values in the cell indicate the following:
True negative (TN): The number of observations that are predicted to be not comfortable with driverless cars ( \(\hat{y}_i = 0\)) and have observed response of not comfortable (\(y_i = 0\)) .
False negative (FN): The number of observations that are predicted to be not comfortable with driverless cars ( \(\hat{y}_i = 0\)) and have observed response of comfortable ( \(y_i = 1\)) .
False positive (FP): The number of observations that are predicted to be comfortable with driverless cars ( \(\hat{y}_i = 1\)) and have observed response of not comfortable ( \(y_i = 0\)) .
True positive (TP): The number of observations that are predicted to be comfortable with driverless cars ( \(\hat{y}_i = 1\)) and have observed response of comfortable ( \(y_i = 1\)) .
Using these definitions, the general form of accuracy computed in Equation 12.1 is
\[
\text{accuracy} = \frac{\text{True negative} + \text{True positive}}{\text{True negative} + \text{False negative} + \text{False positive} + \text{True positive}}
\tag{12.3}\]
Now let’s take a look at additional statistics that help us quantify how well the observations are classified. First, we’ll focus on the column containing those who have observed values \(y_i = 1\).
The sensitivity (true positive rate) is the proportion of those with observed \(y_i = 1\) that were correctly classified as \(\hat{y}_i = 1\). In machine learning contexts, this value is also called recall or probability of detection.
\[
\text{Sensitivity} = \frac{\text{True positive}}{\text{False negative} + \text{True positive}}
\tag{12.4}\]
The false negative rate is the proportion of those with observed \(y_i = 1\) that were incorrectly classified as \(\hat{y}_i = 0\).
\[
\text{False negative rate} = \frac{\text{False negative}}{\text{False negative} + \text{True positive}}
\tag{12.5}\]
The false negative rate is equal to \(1 - \text{Sensitivity}\) and vice versa. The denominators for the false negative rate and the sensitivity are the total number of observations with observed response \(y_i = 1\). In terms of our analysis, this is the total number of people who responded they are comfortable with driverless cars in the General Social Survey.
Next, we look at the column of containing those who have observed values of \(y_i =0\).
The specificity (true negative rate) is the proportion of those with observed \(y_i = 0\) who were correctly classified as \(\hat{y}_i = 0\).
\[
\text{Specificity} = \frac{\text{True negative}}{\text{True negative} + \text{False positive}}
\tag{12.6}\]
The false positive rate is the proportion of those with observed \(y_i = 0\) who were incorrectly classified as \(\hat{y}_i = 1\). In machine learning contexts, this value is also called the probability of false alarm.
\[
\text{False positive rate} = \frac{\text{False positive}}{\text{True negative} + \text{False positive}}
\tag{12.7}\]
The false positive rate is equal to \(1 - \text{specificity}\). The denominators for the specificity and false positive rate are the total number of observations with observed response \(y_i = 0\). In terms of our analysis, this is the total number of people who responded they are not comfortable with driverless cars in the General Social Survey.
The values shown thus far quantify how well observations are classified based on the observed response. Another question that is often of interest is among those with predicted class of \(\hat{y}_i = 1\), how many actually have observed values of \(y_i = 1\)? This value is called the precision.
\[
\text{Precision} = \frac{\text{True positive}}{\text{False positive} + \text{True positive}}
\tag{12.8}\]
Now the denominator is the number of observations that have a predicted class \(\hat{y}_i = 1\), the second row in the Table 12.5. In the context of our analysis, the precision is how many of the individuals who are predicted to be comfortable with driverless cars actually responded on the General Social Survey that they are comfortable with driverless cars. If we’re using the model to identify individuals for a targeted marketing campaign, the precision can be useful in quantifying whether the marketing will generally capture those who are actually comfortable with driverless cars or if a large proportion would be aimed at those who actually aren’t comfortable with driverless cars and likely won’t become robotaxi customers.
Use Table 12.4 to compute the following:
Sensitivity
Specificity
Precision
We have shown how we can derive a lot of useful information from the confusion matrix. As we use the confusion matrix to evaluate how well observations are classified; however, we need to keep in mind that the confusion matrix is determined based on the model predictions and the threshold for classification. For example, in Table 12.6, we see a confusion matrix for the same model in (aidrive-comfort-fit?) using the threshold of 0.3.
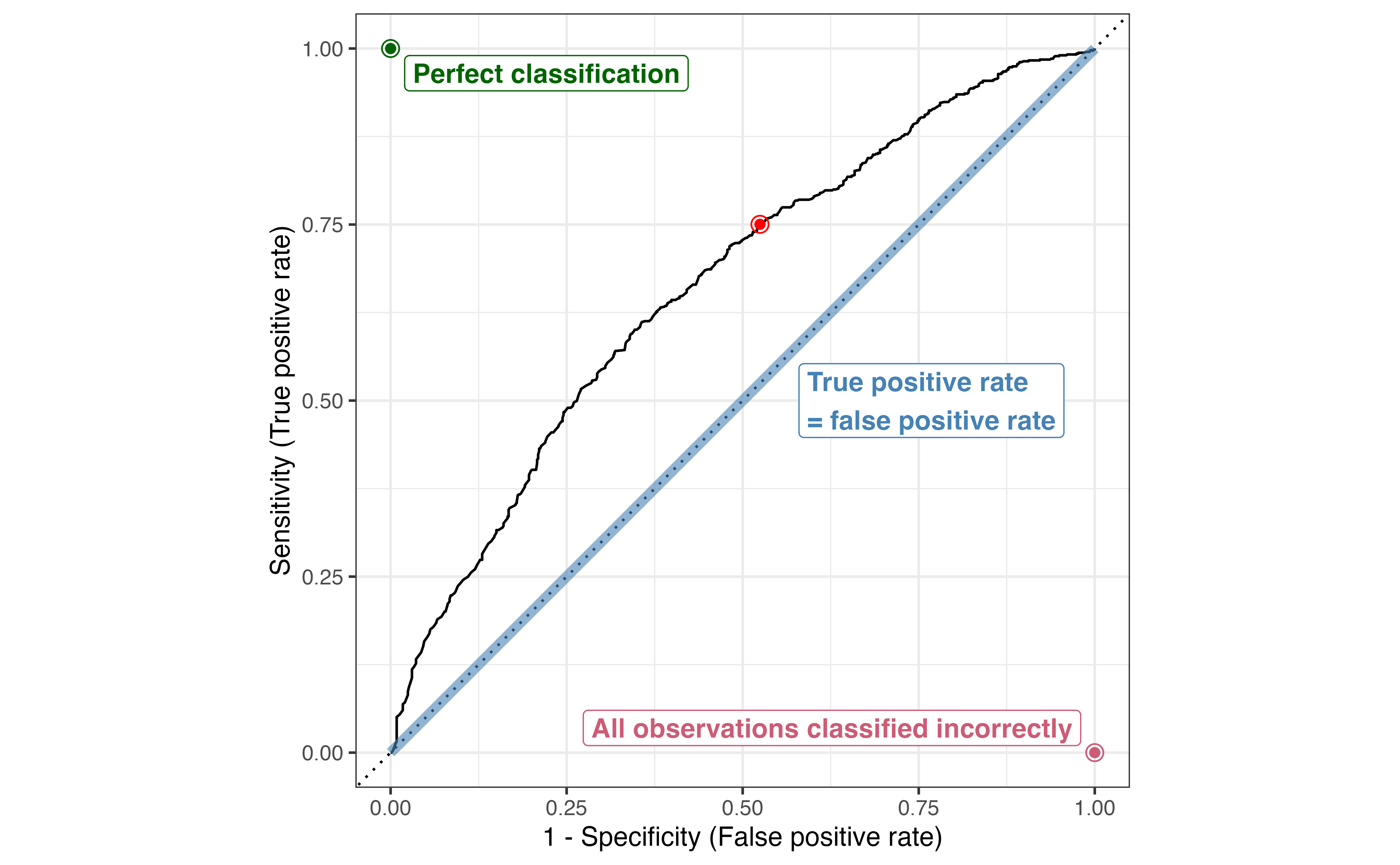
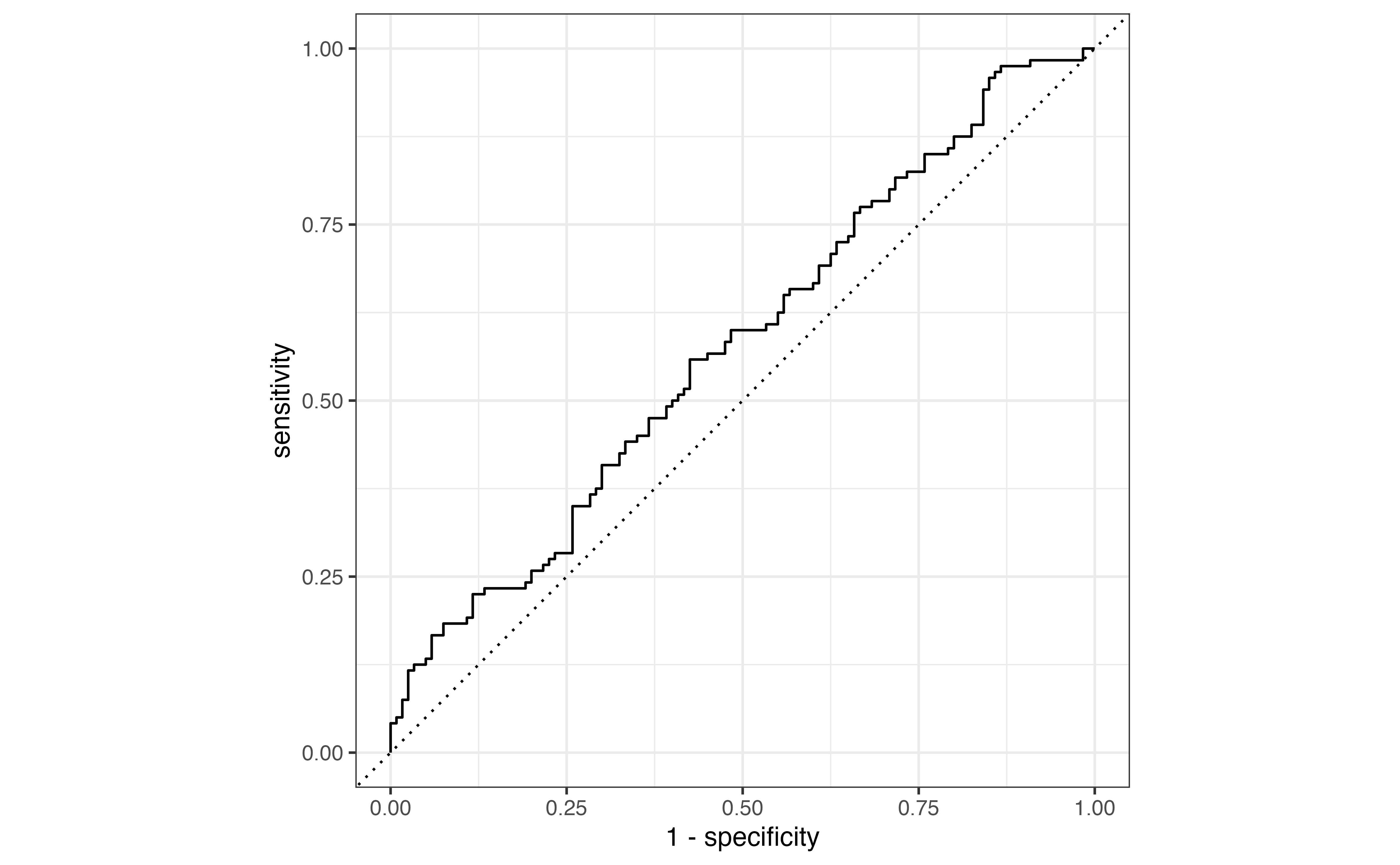
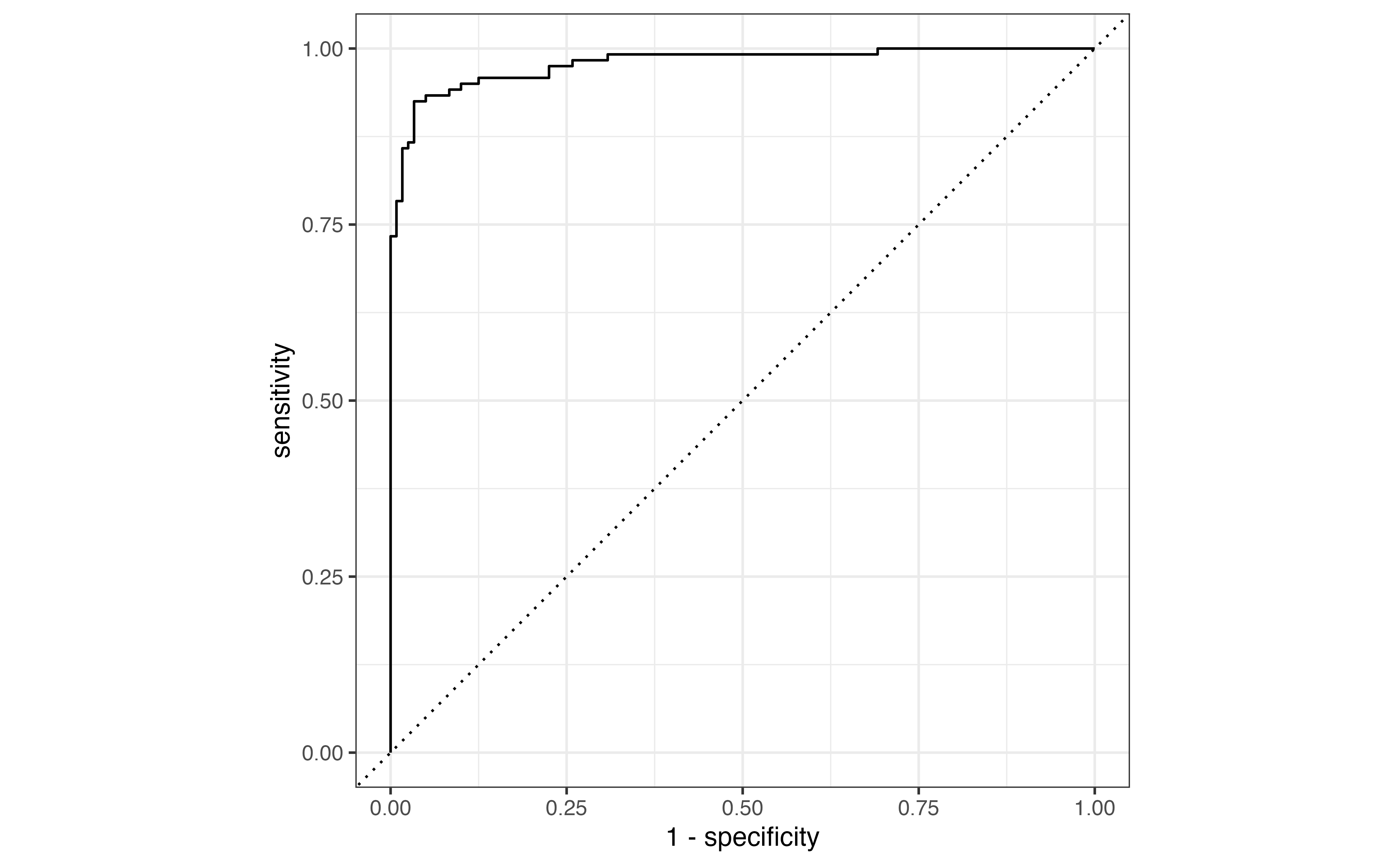
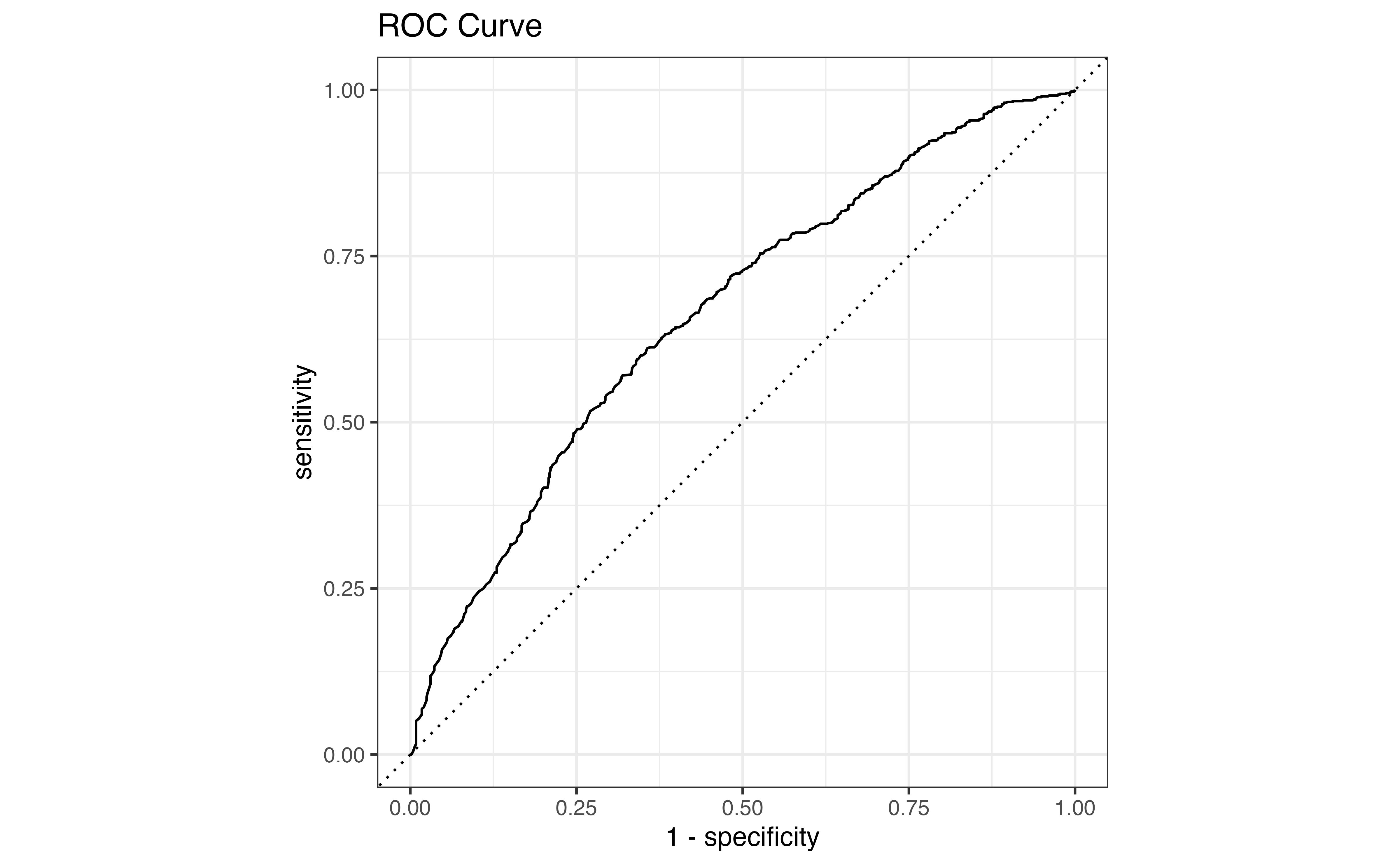
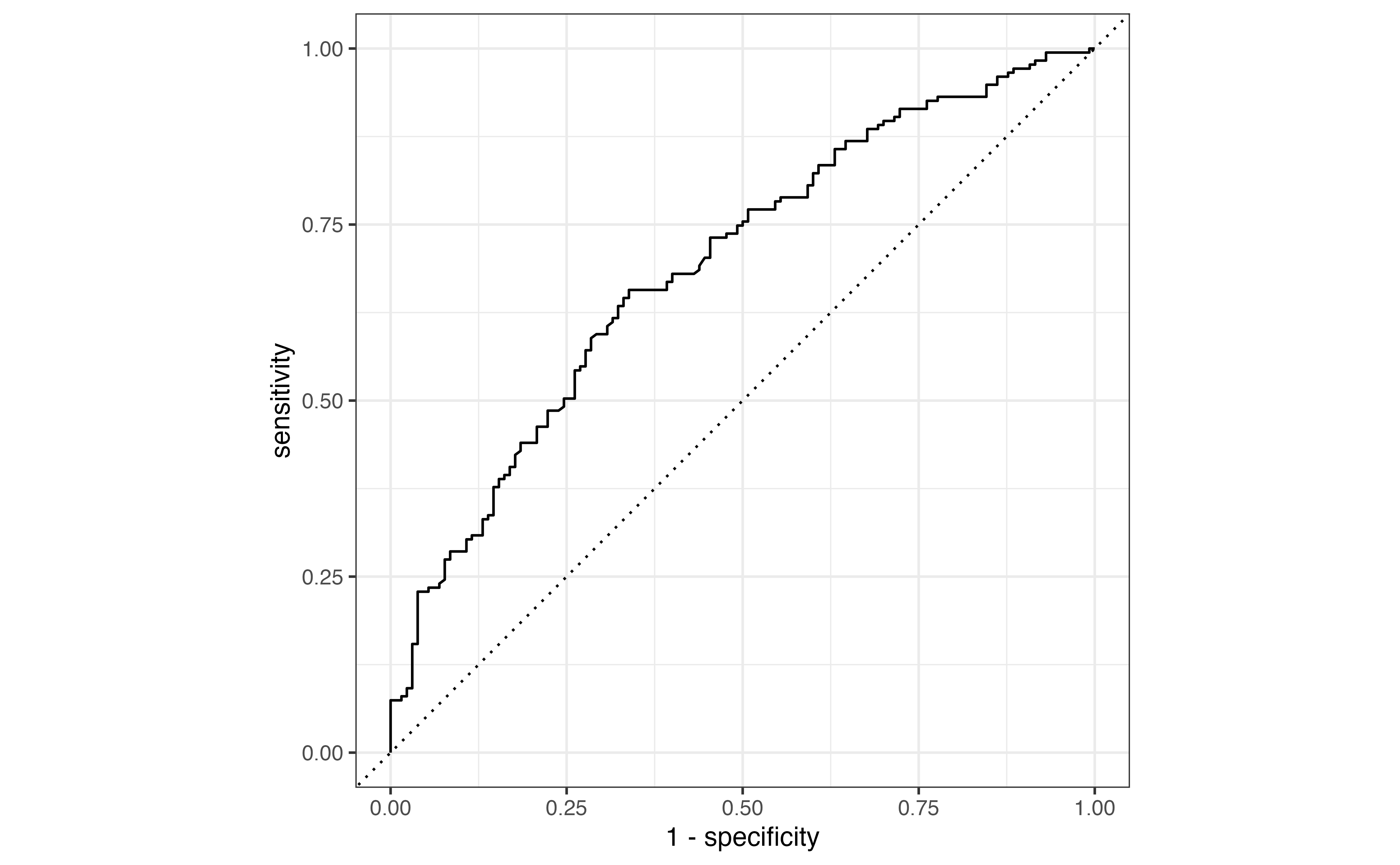
Due to the low threshold, there are many more observations classified as \(\hat{y}_i = 1\) compared to Table 12.4. The accuracy rate is now 58.1% and the misclassification rate is 41.9% even though the model hasn’t changed. From this example, we see that even if the model is unchanged, the metrics computed from the confusion matrix will differ based on the threshold. Therefore, we would like a way to evaluate the model performance independent from the choice of threshold.